This is the blog for Disentangling Target-Side Transfer and Regularization in Multilingual Machine Translation (EACL 2024).
To help every reader better understand our paper, I will go though five questions from shallow to deep to “step-by-step” show our key findings.
Q1: What is Multilingual Machine Translation?
Multilingual Machine Translation (MMT) enables a single model (usually encoder-decoder architecture) to translate multiple source languages into different target languages. MMT has been shown for several advantages: (1) Greatly benefit low-resource language pairs due to knowledge transfer from similar high-resource translation tasks; (2) Relatively compact, allowing one single model to handle multiple translation tasks;
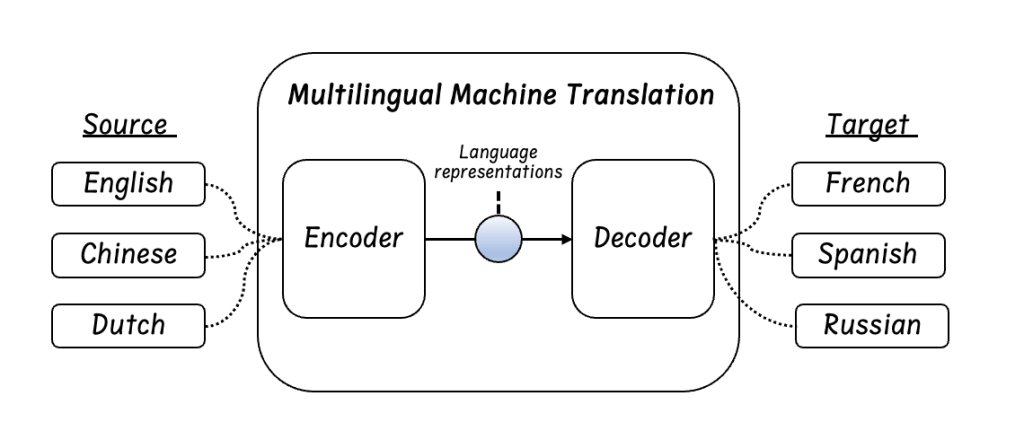
To understand the mechanisms of many-to-many MMT, we usually break down it into (a) Many-to-one MMT, translating different source languages into one target language; (b) One-to-many MMT, translating one single source language into different target languages.
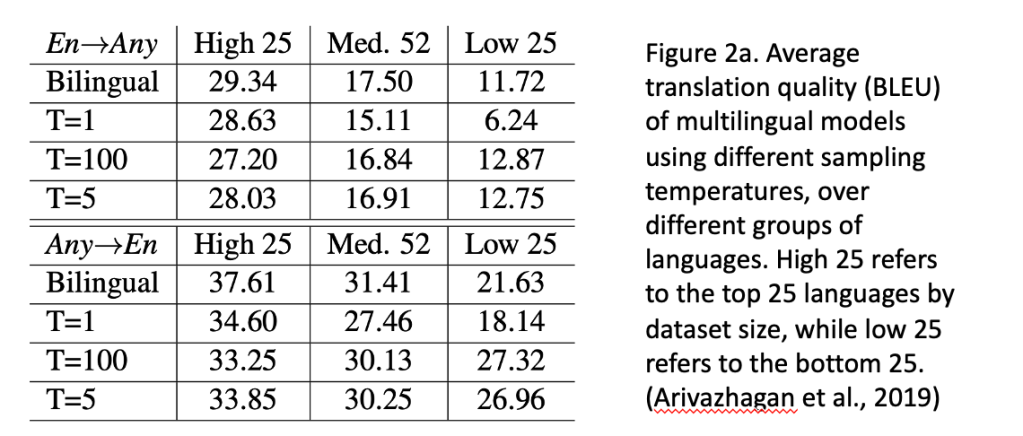
However, results from previous research work all indicate improvements in one-to-many translation compared to many-to-one translation are only marginal and sometimes even negligible (Fig 2).
This leads to our second research question 👇
Q2: Why improvements in one-to-many translation are minimal?
Let’s go one step back to view the architecture of one-to-many translation (Fig 3). Unlike the many-to-one translation, where the decoder only needs to learn one target language, i.e., one single target distribution, the decoder in one-to-many translation needs to learn to map mixed language representations from the encoder into different target languages. This multi-task problem increases the challenge of knowledge transfer on the target-side. Instead of leveraging and sharing similar lexical or linguistic information in the encoder in many-to-one translation, the decoder in one-to-many translation more focuses on generate language-specific representations.
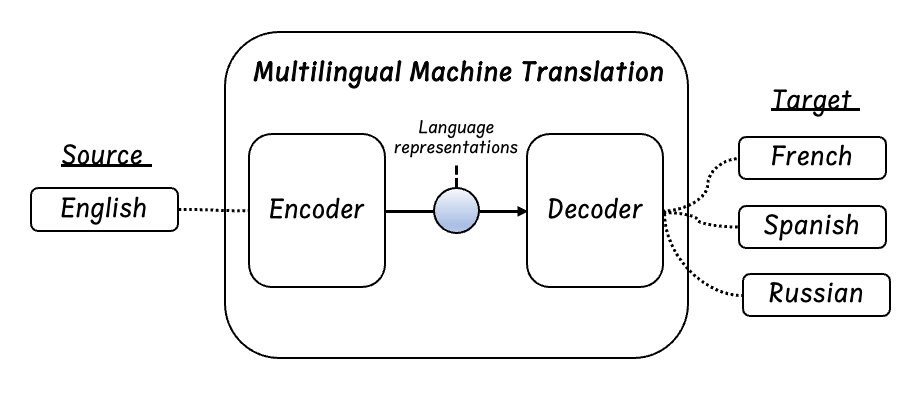
Such difficulty of target-side knowledge transfer and minimal improvements in one-to-many translation result in the hypothesis of knowledge transfer cannot occur on the target-side (Arivazhagan et al., 2019), the observed improvements might be caused by other factors, e.g. increasing source data.
This leads to our third question, which is also our first main research question in our paper:
Q3: Does knowledge transfer really occur on the target-side?
To answer this question, we conduct a comprehensive series of controlled experiments: choosing one main language pair (e.g. English into German), and train this main language pair with different auxiliary target languages (from linguistic similar to linguistic distant), e.g. (1) English into Dutch (same language family and written script); (2) English into Estonia (different language family, same written script); (3) English into Russian (different language family and written script); (4) English into Chinese (different language family and written script).
The results shown in below table vividly show:
(1) Target-side transfer do occurs in Multilingual Machine Translation. Increasing the size of similar target languages can enhance the positive knowledge transfer than distant ones. e.g. sampled low-resource English into German translation can be improved by 9 BLEU points when training with English into Dutch data while only 6 BLEU points when using distant target languages, e.g. Chinese.
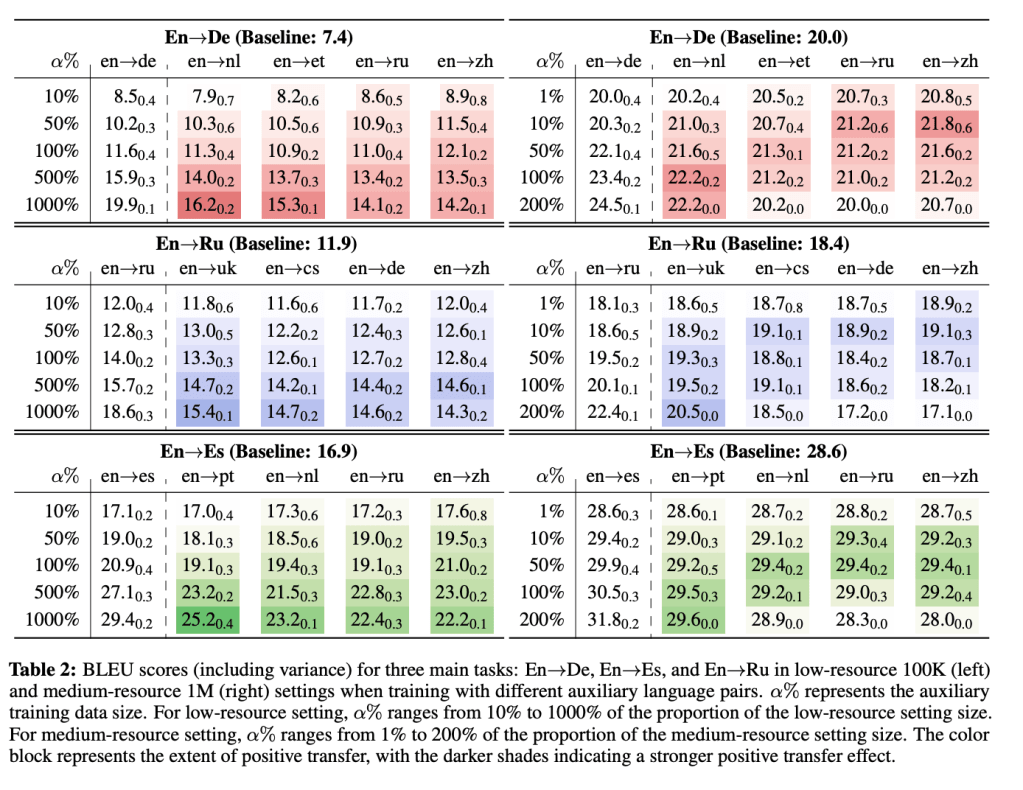
(2) Such target-side transfer pattern do gradually becomes inevident with an increasing of the data size, see the right of the table with medium-resource main tasks. However, we could still see improvements when increasing the size of similar auxiliary tasks, but negative transfer from the distant ones.
(3) Surprisingly, we could also see small amounts of distant target data can achieve similar improvements as maximum positive transfer does. e.g. Sampled medium-resource English into German task can benefit similarly from 10% English into Chinese and 200% of English into Dutch.
The third finding surprisingly shows that target-side transfer cannot explain all the improvements in one-to-many translation. The small size of distant data, which exhibit the minimal positive transfer ability, surprisingly can lead to improvements. This leads to our next research question:
Q4: How does distant data play a role in MMT?
Although previous research indicate that distant target data is the root for negative transfer, we show that certain amounts of distant data can also lead to surprising performance gains which can be attributed to regularization.
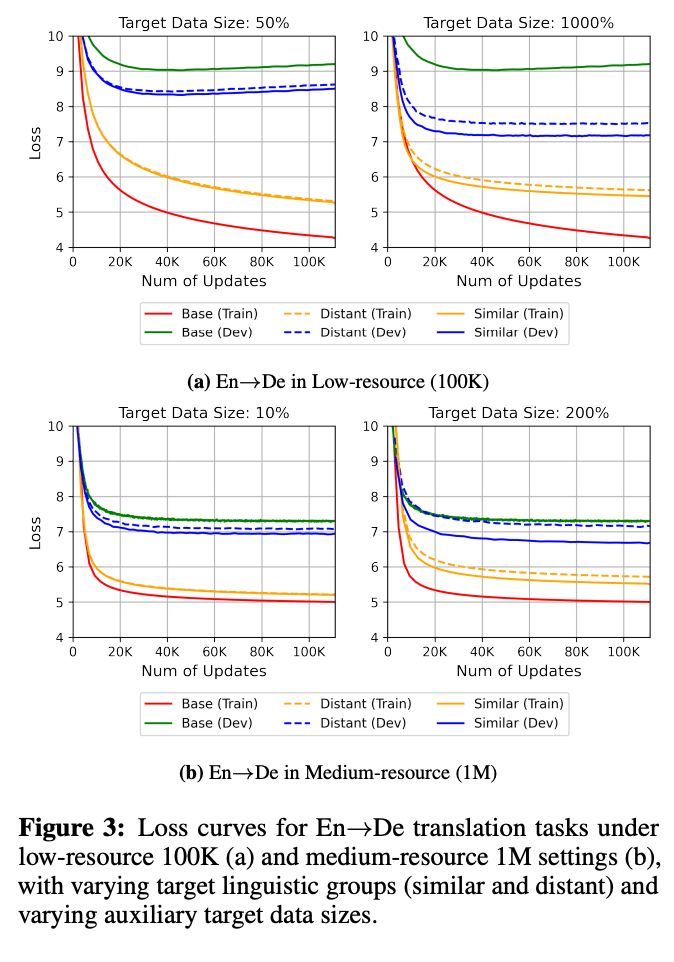
Our results in Table 2 clearly show that small size of distant data can most benefit the main task translation performance. To further show their regularization effect, we first show their ability to reduce the generalization errors (compared with similar task).
We could find here is that distant target data could reduce the validation loss as well as the similar tasks. This also supports the performance gains in Table 2.
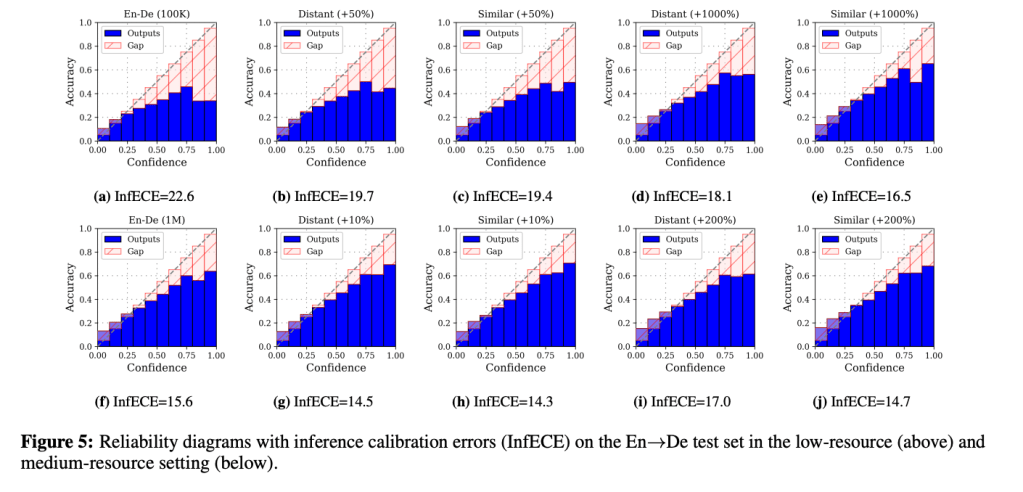
Another benefit of regularization is to improve inference calibration. Calibration measures model’s alignment of its accuracy and confidence. If the model’s confidence is larger than its accuracy, we could consider the model is over-confident, i.e., overfitting.
The below figure shows how inference calibration of the main task changes when training with different auxiliary tasks. What we could clear find here is that small amounts of distant tasks can improving model calibration to benefit the translation tasks. Although similar tasks can also improve model calibration, it is not clear such improvement is induced by improving accuracy or penalizing confidence.
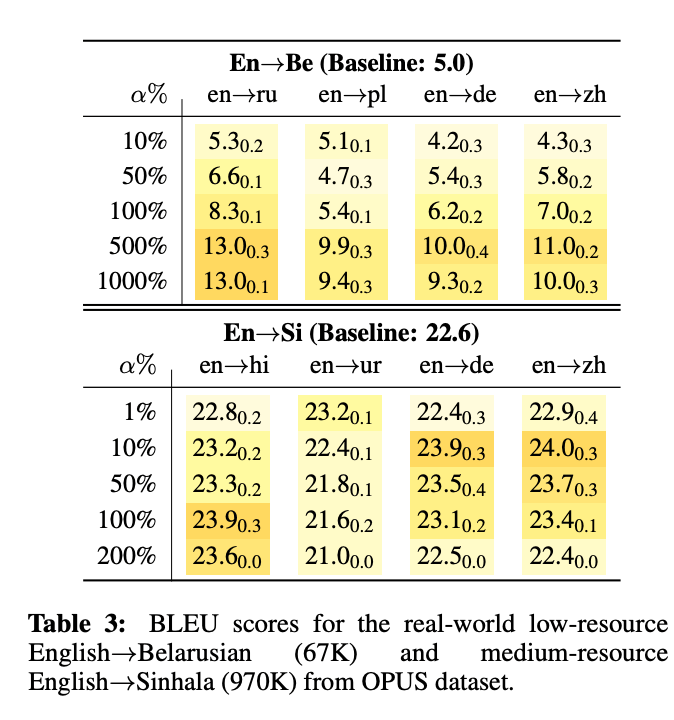
Q5. How do our findings apply to the real-world scenarios?
We show that positive target-side transfer do occurs, and highly correlates with linguistic similarity and auxiliary data size. In Table below, assuming you have a real-world low-resource task (English into Sinhala, real-world low-resource data), you can use a large amounts of similar auxiliary data (English into Hindi) to improve it. However, using certain amounts (10% here) of distant data (English into Chinese) can also bring you unexpected results!
Thanks for reading :))
